How to reduce storage costs on Amazon S3
Once on the real project, my colleagues had discussions with our customer about how to lower monthly costs for its future infrastructure in AWS. Since we have changed some full-fledged solutions by AWS to cheaper self-managed open-source software, there were not many possibilities left. I was thinking about how I could improve it from time to time, and suddenly remembered one interesting feature I learned while preparing for one AWS certification years ago.
Which one? A little guidance – we have different services in our architecture and as a good practice, we log information and store them in S3 buckets. Logs for streaming services, monitoring, access logs, etc. The more information you store, the more you pay – of course.
So what to do with it? Older logs become irrelevant after some time, so why not remove some old, unnecessary files? Right, that’s something we know.
But which other way could we lower the costs? Oh, yes – we’ll use different Storage Classes! This beautiful option allows us to store logs in different storage classes which are cheaper than each other. Moreover, we can even automate the removal of old files.
Nội Dung Chính
Let’s take it one by one – Storage Classes
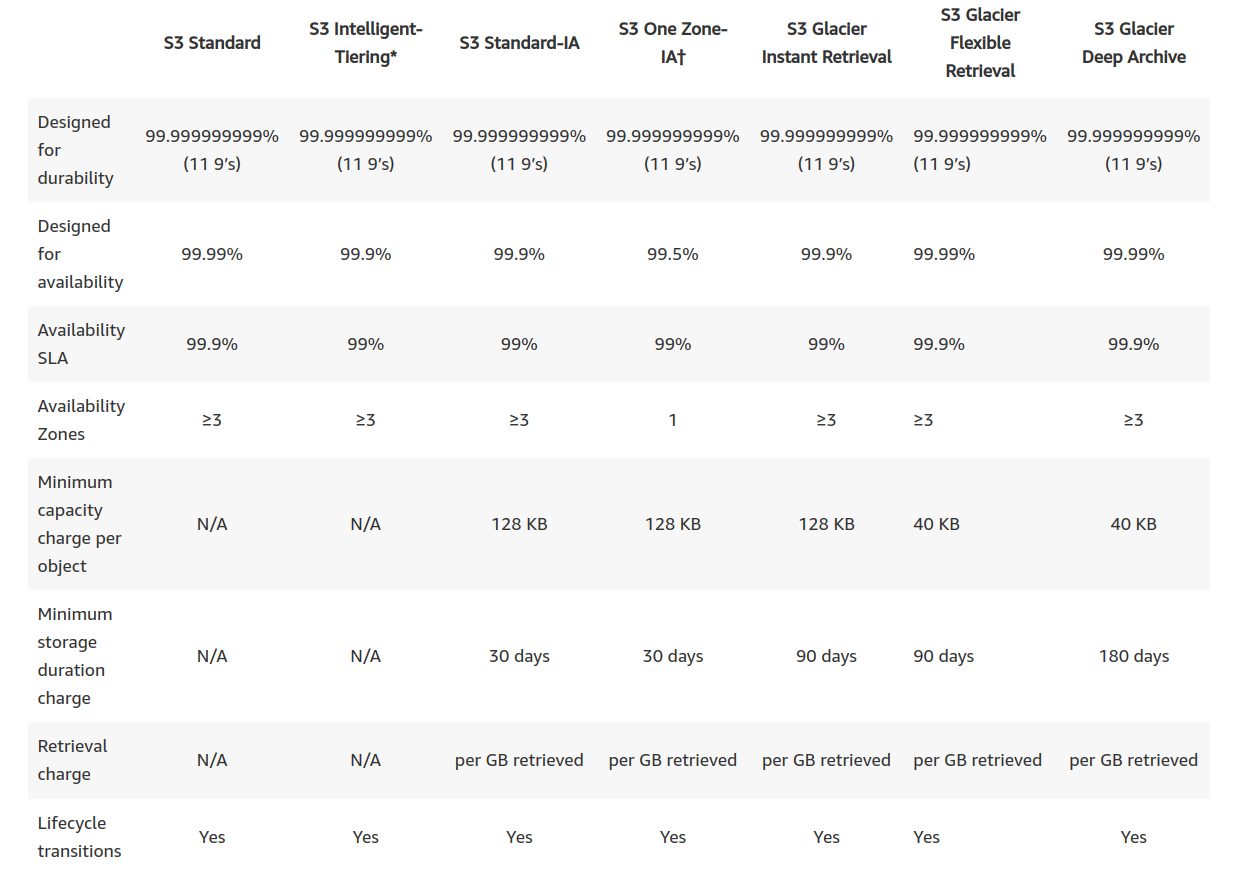
AWS offers several different Storage Classes:
S3 Standard
This is the default storage class used to store frequently accessed data.
S3 Intelligent-Tiering
Automatically moves data to the most cost-effective access tier based on access frequency, without performance impact, retrieval fees, or operational overhead.
– higher request price
S3 Infrequent Access (S3-IA)
Ideal for infrequently accessed data (such as old logs in our case).
– S3 Standard Infrequently Accessed (S3 Standard-IA): redundancy across multiple AZ
– S3 One Zone Infrequently Accessed (S3 One Zone-IA): has data stored in only one AZ
S3 Glacier Instant Retrieval
– one can save up to 68% on storage costs compared to using the S3 Standard-IA storage class when your data is accessed once per quarter.
– for archive data that needs immediate access
S3 Glacier Flexible Retrieval (Formerly S3 Glacier)
– for archive data that is accessed 1—2 times per year and is retrieved asynchronously
– retrieval times from minutes to hours
S3 Glacier Deep Archive
– cheapest option
– minimum retrieval time of 12 hours
– for customers in highly-regulated industries, such as financial services, healthcare, and public sectors that retain data sets for 7-10 years or longer to meet regulatory compliance requirements
OK, and how does this help? Move them and save costs!
After some time, log files or other objects might have been viewed less often and therefore would be efficient to move them into a different Storage Class to save costs.
A single S3 bucket can contain objects stored across different Storage Classes.
To help with this in an automated way, AWS comes with Lifecycle policies.
Lifecycle policies can be divided into two:
- Transition policy – moves objects between different storage classes
- Expiration policy – defines how long to keep objects until they get deleted
For a given S3 bucket this can be defined manually using AWS Management Console, or using IaC tools such as Terraform configured in either the resource aws_s3_bucket with the parameter lifecycle_rule (example below) or in the standalone resource aws_s3_bucket_lifecycle_configuration:
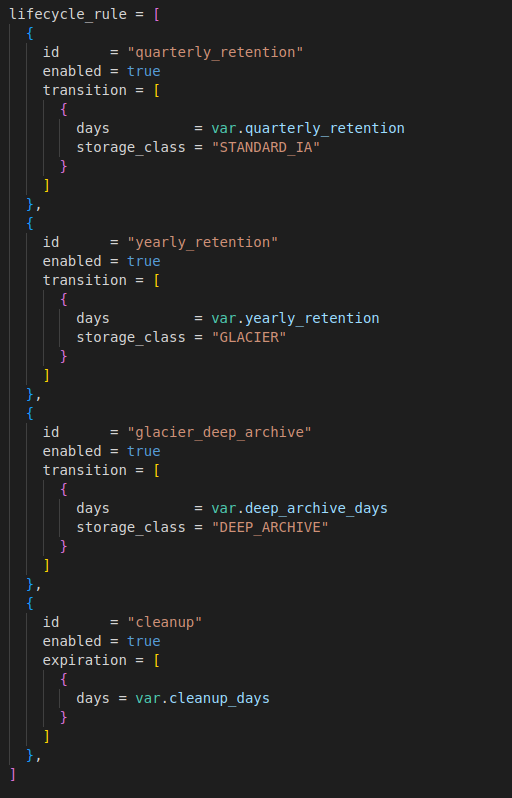
where Variable value represents number of days after object creation.
Besides of costs for the storage itself, you will be charged also for:
S3 Lifecycle Transition requests – For example, transitioning data from S3 Standard to
S3 Standard-IA will be charged $0.01 per 1,000 requests.
Storage overhead for metadata – When you transition objects to the S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive storage class, a fixed amount of storage is added to each object to accommodate metadata for managing the object.
Amazon S3 adds 8 KB of storage for the name of the object + 32 KB of storage for index and related metadata.
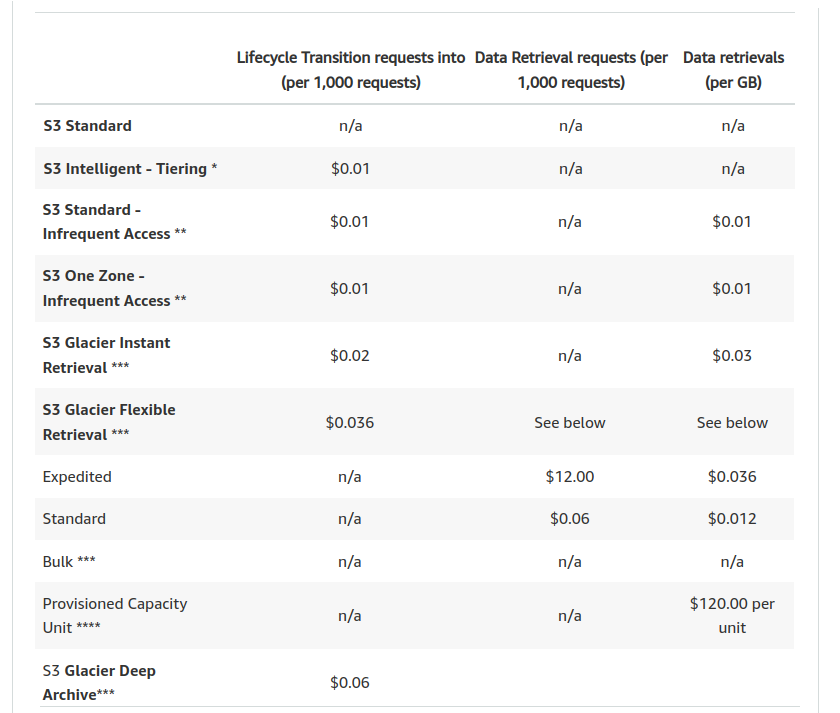
Example comparison:
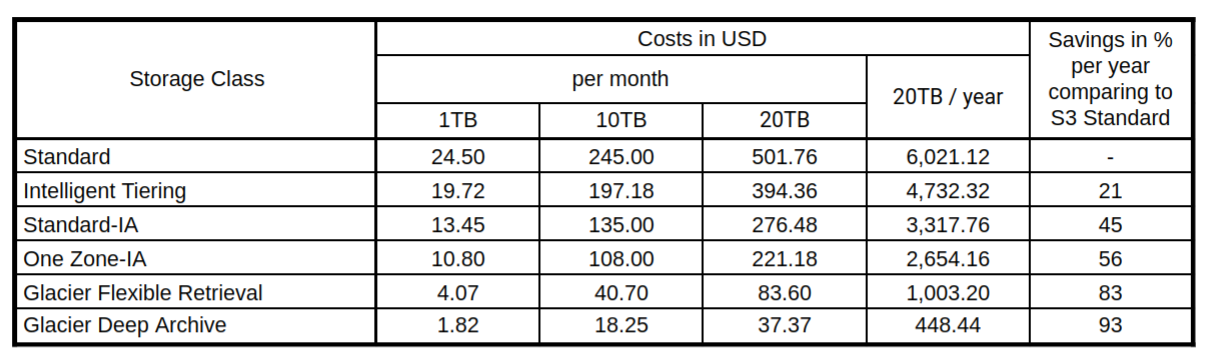
Note: For S3 Intelligent tiering was Percentage of Storage in INT-Frequent Access Tier and INT-Infrequent Access Tier set equally to 50% / 50%





