Amazon S3 là gì ? Tổng quan dịch vụ Amazon Simple Storage Service – Technology Diver
Amazon S3 là gì ? Tổng quan dịch vụ Amazon Simple Storage Service – Cuongquach.com | Bạn làm quản trị hệ thống Cloud AWS thì hẳn phải nắm được dịch vụ Amazon S3 . Vì đây là một trong những dịch vụ lưu trữ dữ liệu cloud quen thuộc của Amazon dành cho người dùng tuỳ theo các mục đích khác nhau. Thậm chí bạn cũng có thể sử dụng Amazon S3 cho các dịch vụ ngoài AWS khi có nhu cầu lớn về lưu trữ dữ liệu mà băn khoăn nên sử dụng dịch vụ của ai .

Amazon S3 là gì ?
![]()
Amazon Simple Storage Service (Amazon S3) là một dịch vụ lưu trữ đối tượng cung cấp khả năng thay đổi theo quy mô, tính khả dụng của dữ liệu, bảo mật và hiệu năng hàng đầu trong lĩnh vực. Điều này có nghĩa là khách hàng thuộc mọi quy mô và lĩnh vực có thể sử dụng dịch vụ này để lưu trữ và bảo vệ bất kỳ lượng dữ liệu nào cho nhiều trường hợp sử dụng khác nhau, chẳng hạn như trang web, ứng dụng di động, sao lưu và khôi phục, lưu trữ, ứng dụng doanh nghiệp, thiết bị IoT và phân tích dữ liệu hớn.
Amazon S3 cung cấp các tính năng quản lý dễ sử dụng, nhờ đó, bạn có thể tổ chức dữ liệu và cấu hình các kiểm soát truy cập được tinh chỉnh để đáp ứng yêu cầu cụ thể của doanh nghiệp, tổ chức và yêu cầu về tuân thủ. Amazon S3 được thiết kế để đảm bảo độ bền 99,999999999% (11,9’s downtime) và lưu trữ dữ liệu của hàng triệu ứng dụng cho các công ty trên toàn thế giới.
Các khái niệm cần nắm trong Amazon S3
Bucket
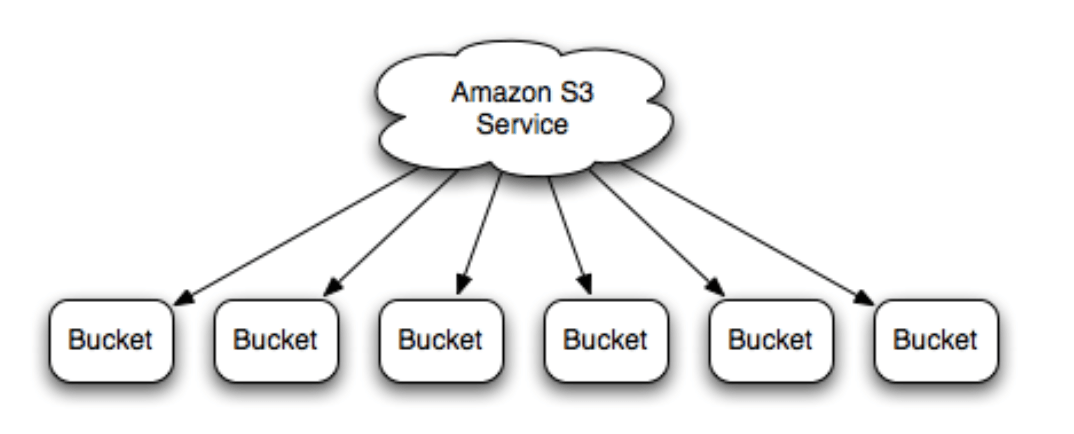
Dữ liệu trên Amazon S3 được hệ thống hoá theo khái niệm Bucket:
- Amazon S3 lưu trữ dữ liệu như một Object.
- Một Bucket là một đơn vị lưu trữ logical trên S3.
- Một Bucket sẽ chứa các object, trong đó Object sẽ chứa dữ liệu (data) và metadata miêu tả về dữ liệu đó.
- Bạn có thể chỉ định vị trí địa lý khu vực mà Bucket của bạn tạo ra sẽ được lưu trữ ở Amazon S3 khu vực đó.
- Mỗi bucket sẽ có một cái tên toàn cục (global) độc nhất. Điều đó có nghĩa nếu tên bucket đã được xài thì không tài khoản AWS nào ở bất kì khu vực nào có thể đặt lại tên đó.
Như thế thì một bucket giống như một container cho các object lưu trữ trên Amazon S3. Mỗi object sẽ được chứa trong một bucket.
Ví dụ :
– Nếu object tên ‘photos/puppy.jpg’ được chứa trong bucket tên ‘cuongqc’, thì lúc này dữ liệu của bạn có thể được truy xuất qua URL :
http://cuongqc.s3.amazonaws.com/photos/puppy.jpg
Vậy bucket sinh ra dùng cho một số mục đích như:
- Quản lý Amazon S3 namepsace.
- Xác định được tài khoản nào chịu trách nhiệm lưu trữ dữ liệu và chuyển dữ liệu để tính phí sử dụng
- Xác định được các quyền kiểm soát truy cập.
- Tiện lợi trong việc báo cáo sử dụng.
Key
Một key là một chuỗi định danh ID cho một Object trong một Bucket. Mỗi Object trong bucket sẽ có chính xác một key. Mỗi Object trong Amazon S3 sẽ có một địa chỉ truy cập độc nhất bằng cách kết hợp giữa các thông tin như web service enpoint, tên bucket, key, version.
Ví dụ
- URL truy cập Object ‘AmazonS3.wsdl’ : http://doc.s3.amazonaws.com/2006-03-01/AmazonS3.wsdl
- Tên bucket : doc
- Key : 2006-03-01/AmazonS3.wsdl
Object
Object (đối tượng) là khái niệm cơ bản về một thực thể dữ liệu được lưu trữ trong Amazon S3. Các object sẽ bao gồm object dữ liệu (object data) và metadata. Về phần object dữ liệu thì S3 chỉ lưu trữ không quan tâm dữ liệu đó là gì. Còn lại thì phải có “metadata” là dữ liệu thông tin theo kiểu ‘name-value’ dùng để miêu tả về object ví dụ như : ngày chỉnh sửa, loại dữ liệu,…. Mỗi một Object sẽ có một ID độc nhất nằm trong một bucket.
Khu vực (region)
Bạn có thể chọn khu vực địa lý mà Amazon S3 sẽ chứa các bucket mà bạn khởi tạo. Điều này có ích cho việc tối ưu hoá về độ trễ, chi phí … Object khi lưu ở một khu vực cụ thể sẽ không bao mất cho đến khi bạn xoá hoặc chuyển các Object đó sang khu vực khác.
Bạn cần cân nhắc 4 yếu tố sẽ giúp bạn chọn ra được khu vực (region) Amazon S3 sẽ lưu trữ giúp tối ưu và hiệu quả, đó là:
- Pricing (Giá)
- User/Customer Location (Nơi khách hàng sử dụng dịch vụ)
- Latency (Độ trễ)
- Service Availability (Tính khả dụng dịch vụ)
Quy trình sử dụng Amazon S3 cơ bản

- Bước 1: tạo một bucket
- Bước 2: thêm một object vào bucket
- Bước 3: xem thông tin về object
- Bước 4: nếu muốn di chuyển object thì thực hiện thao tác object
- Bước 5: nếu muốn xoá object và bucket thì thực hiện thao tác xoá object/bucket.
Ưu điểm của dịch vụ Amazon S3
Amazon S3 được thiết kế các tính năng tối giản nhằm đạt được mục tiêu đơn giản và nhanh gọn. Sau đây là một số ưu điểm của Amazon S3:
- Tạo Buckets: tạo và đặt tên một Bucket sẽ chứa dữ liệu. Bucket là khái niệm cơ bản trong Amazon S3 dành cho việc lưu trữ dữ liệu.
- Lưu trữ dữ liệu trong Bucket : bạn có thể lưu trữ vô hạn các loại dữ liệu khác nhau trong một bucket. Mỗi dữ liệu của bạn sẽ như là một Object và muốn up nhiêu cũng được. Mỗi object có thể chứa tới 5TB dữ liệu.
- Tải dữ liệu : bạn có thể tải dữ liệu của bạn về bất cứ lúc nào, thậm chí là cho phép người khác tải dữ liệu của bạn đang nằm trong Amazon S3 Bucket nữa cơ.
- Phân quyền : phân quyền cho phép hoặc từ chối quyền hạn upload/download đối với dữ liệu nằm trong Amazon S3 Bucket của bạn.
- Giao diện tương tác tiêu chuẩn : bạn có thể sử dụng REST hoặc SOAP để thiết kế tương tác từ ứng dụng của bạn đến Amazon S3 qua các công cụ lập trình phát triển.
- Tính ổn định: Nó được thiết kế để chịu được các hỏng hóc và phục hồi hệ thống rất nhanh với thời gian tối thiểu. Amazon cung cấp một thỏa thuận cấp dịch vụ (service-level agreement – SLA) để duy trì tính sẵn sàng ở mức 99.99 phần trăm.
- Đơn giản: Dễ dùng S3 được xây dụng trên các khái niệm đơn giản và cung cấp tính mềm dẻo cao cho việc phát triển các ứng dụng của bạn. Bạn có thể xây dựng các lược đồ lưu trữ phức tạp hơn, nếu cần, bằng cách thêm các hàm vào các thành phần của S3.
- Tính mở rộng: Thiết kế của S3 cung cấp một cấp độ cao về tính mở rộng và cho phép sự điều chỉnh dễ dàng trong dịch vụ khi lượng truy cập vào ứng dụng web của bạn tăng đột biến với lưu lượng khổng lồ.
- Rất Rẻ: Chi phí sử dụng S3 rất cạnh tranh với các giải pháp của công ty và cá nhân khác trên thị trường.
Lợi ích của dịch vụ Amazon S3
- Hiệu năng, khả năng thay đổi theo quy mô, tính khả dụng và độ bền hàng đầu trong lĩnh vực
Tăng và giảm quy mô tài nguyên lưu trữ của bạn để đáp ứng nhu cầu hay thay đổi, mà không cần các khoản đầu tư trả trước hay chu kỳ thu mua tài nguyên. Amazon S3 được thiết kế để đảm bảo độ bền dữ liệu 99,999999999% (11 9’s) vì dịch vụ này tự động tạo và lưu trữ bản sao của tất cả đối tượng S3 trên nhiều hệ thống. Điều này có nghĩa là dữ liệu của bạn khả dụng khi cần và được bảo vệ khỏi các sự cố, lỗi và mối đe dọa.
- Nhiều lớp lưu trữ tiết kiệm chi phí
Tiết kiệm chi phí mà không phải hi sinh hiệu suất bằng cách lưu trữ dữ liệu trên Các lớp lưu trữ S3 hỗ trợ các cấp độ truy cập dữ liệu khác nhau ở mức giá tương ứng. Bạn có thể sử dụng Phân tích lớp lưu trữ S3 để khám phá dữ liệu cần di chuyển sang lớp lưu trữ có chi phí thấp hơn dựa trên các cấu trúc truy cập và cấu hình một chính sách Vòng đời S3 để thực thi việc truyền dữ liệu. Bạn cũng có thể lưu trữ dữ liệu với các cấu trúc truy cập không xác định hoặc hay thay đổi trong S3 Thông minh-Phân bậc, dịch vụ này phân bậc đối tượng dựa trên các cấu trúc truy cập hay thay đổi và tự động tiết kiệm chi phí.
- Bảo mật, tính tuân thủ và khả năng kiểm tra chưa từng có
Lưu trữ dữ liệu của bạn trong Amazon S3 và ngăn chặn truy cập dữ liệu trái phép với các tính năng mã hóa và công cụ quản lý truy cập. Bạn cũng có thể sử dụng Amazon Macie để xác định dữ liệu nhạy cảm trong bộ chứa S3 của mình và phát hiện yêu cầu truy cập bất thường. Amazon S3 duy trì các chương trình tuân thủ, chẳng hạn như PCI-DSS, HIPAA/HITECH, FedRAMP, Chỉ thị bảo vệ dữ liệu của Liên minh châu Âu và FISMA, để giúp bạn đáp ứng các yêu cầu về quy định. AWS cũng hỗ trợ nhiều khả năng kiểm tra để giám sát các yêu cầu truy cập vào tài nguyên S3 của bạn.
- Các công cụ quản lý dùng để kiểm soát dữ liệu chi tiết
Phân loại, quản lý và báo cáo về dữ liệu của bạn bằng các tính năng như: Phân tích lớp lưu trữ S3 để phân tích các cấu trúc truy cập; các chính sách Vòng đời S3 để chuyển đối tượng sang lớp lưu trữ có chi phí thấp hơn; Sao chép liên khu vực S3 để sao chép dữ liệu vào khu vực khác; Khóa đối tượng S3 để áp dụng ngày duy trì đối với ứng dụng và bảo vệ để ứng dụng không bị xóa; và Kho S3 để tìm hiểu về đối tượng được lưu trữ của bạn, siêu dữ liệu và trạng thái mã hóa của các đối tượng đó. Bạn cũng có thể sử dụng S3 Batch Operations để thay đổi thuộc tính đối tượng và thực hiện tác vụ quản lý lưu trữ cho hàng tỷ đối tượng. Do Amazon S3 có liên kết với AWS Lambda, bạn có thể ghi nhật ký hoạt động, định nghĩa cảnh báo và tự động hóa luồng công việc mà không phải quản lý thêm cơ sở hạ tầng nào.
- Dịch vụ truy vấn tại chỗ cho phân tích
Chạy phân tích dữ liệu lớn trên các đối tượng S3 của bạn (và các tập hợp dữ liệu khác trong AWS) với dịch vụ truy vấn tại chỗ của chúng tôi. Sử dụng Amazon Athena để truy vấn dữ liệu S3 với các biểu thức SQL tiêu chuẩn và Amazon Redshift Spectrum để phân tích dữ liệu được lưu trữ trên kho lưu trữ dữ liệu AWS và tài nguyên S3 của bạn. Bạn cũng có thể sử dụng S3 Select để truy xuất các tập hợp nhỏ siêu dữ liệu đối tượng thay vì toàn bộ đối tượng và tăng tới 400% hiệu suất truy vấn.
- Dịch vụ lưu trữ đám mây được hỗ trợ nhiều nhất
Lưu trữ và bảo vệ dữ liệu của bạn trong Amazon S3 bằng cách làm việc với đối tác từ Mạng lưới đối tác AWS (APN) — cộng đồng nhà cung cấp dịch vụ tư vấn và công nghệ lớn nhất. APN nhận diện các đối tác di chuyển truyền dữ liệu sang Amazon S3 và đối tác lưu trữ cung cấp giải pháp tích hợp S3 để phục vụ lưu trữ chính, sao lưu và khôi phục, lưu trữ và khôi phục sau thảm họa. Bạn cũng có thể mua giải pháp tích hợp AWS trực tiếp từ AWS Marketplace, tại đây có hơn 250 dịch vụ dành riêng cho lưu trữ.
Trường hợp sử dụng Amazon S3
Sao lưu và phục hồi
Xây dựng các giải pháp sao lưu và khôi phục có thể thay đổi theo quy mô, có độ bền và bảo mật với Amazon S3 và các dịch vụ AWS khác, chẳng hạn như S3 Glacier, Amazon EFS và Amazon EBS, để tăng cường hoặc thay thế các khả năng tại chỗ hiện có. Các đối tác AWS và APN có thể giúp bạn đáp ứng Thời gian khôi phục (Recovery Time Objectives – RTO), Thời điểm khôi phục (Recovery Point Objectives – RPO) và các yêu cầu về tuân thủ. Với AWS, bạn có thể sao lưu dữ liệu đã có trong Đám mây AWS hoặc sử dụng AWS Storage Gateway, một dịch vụ lưu trữ kết hợp để gửi các bản sao lưu dữ liệu tại chỗ sang AWS.
Khôi phục sau thảm họa (DR)
Bảo vệ dữ liệu, ứng dụng và hệ thống CNTT quan trọng đang chạy trong Đám mây AWS hoặc trong môi trường tại chỗ của bạn mà không phải chịu phí tổn của một cơ sở vật lý phụ. Với lưu trữ Amazon S3, Sao chép liên khu vực S3, và các dịch vụ cơ sở dữ liệu, mạng và điện toán AWS khác, bạn có thể tạo các kiến trúc DR để khôi phục nhanh chóng và dễ dàng sau khi mất điện do thảm họa thiên nhiên, sự cố hệ thống và lỗi của con người.
Lưu trữ
Giải phóng cơ sở hạ tầng vật lý và lưu trữ dữ liệu với S3 Glacier và S3 Glacier Deep Archive. Các lớp lưu trữ S3 này duy trì các đối tượng lâu dài với mức giá thấp nhất. Chỉ cần tạo một chính sách S3 Vòng đời để lưu trữ đối tượng trong toàn bộ vòng đời hoặc tải đối tượng trực tiếp lên các lớp lưu trữ. Với S3 Object Lock, bạn có thể áp dụng ngày duy trì với đối tượng để ngăn đối tượng bị xóa và đáp ứng các yêu cầu về tuân thủ. Không giống các thư viện băng từ, S3 Glacier cho phép bạn khôi phục đối tượng đã lưu trữ chỉ trong một phút đối với truy xuất nhanh và 3-5 giờ đối với truy xuất tiêu chuẩn. Quá trình khôi phục khối lượng dữ liệu lớn từ S3 Glacier và khôi phục toàn bộ từ S3 Glacier Deep Archive hoàn tất trong vòng 12 giờ.
Kho dữ liệu và phân tích dữ liệu lớn
Đẩy nhanh quá trình đổi mới bằng cách tạo một kho dữ liệu trong Amazon S3 và trích xuất thông tin chi tiết quan trọng bằng các công cụ machine learning, phân tích và truy vấn tại chỗ. Bạn cũng có thể sử dụng AWS Lake Formation để tạo nhanh một kho dữ liệu và tập trung xác định cũng như thực thi các chính sách bảo mật, quản trị và kiểm tra. Dịch vụ này thu thập dữ liệu ở các cơ sở dữ liệu và tài nguyên S3 của bạn, di chuyển dữ liệu vào một kho dữ liệu mới trong Amazon S3 và dọn dẹp cũng như phân loại dữ liệu bằng các thuật toán machine learning. Mọi tài nguyên AWS đều có thể được tăng quy mô để đáp ứng các kho dữ liệu mở rộng của bạn mà không cần đầu tư trước.
Lưu trữ đám mây lai
Tạo một kết nối liền mạch giữa ứng dụng tại chỗ và Amazon S3 với AWS Storage Gateway để giảm phạm vi của trung tâm dữ liệu và sử dụng quy mô, độ tin cậy và độ bền của AWS, cũng như các khả năng phân tích và machine learning đổi mới của AWS. Bạn cũng có thể tự động hóa quá trình truyền dữ liệu giữa lưu trữ tại chỗ và Amazon S3 bằng AWS DataSync, dịch vụ này có thể truyền dữ liệu ở tốc độ nhanh hơn tới 10 lần so với các công cụ nguồn mở. Một cách khác để hỗ trợ môi trường lưu trữ đám mây lai là làm việc với nhà cung cấp cổng từ APN. Bạn cũng có thể truyền tệp trực tiếp vào hoặc ra khỏi Amazon S3 với AWS Transfer for SFTP — một dịch vụ được quản lý đầy đủ, cho phép trao đổi tệp an toàn với các bên thứ ba.
Dữ liệu ứng dụng dành cho đám mây
Xây dựng các ứng dụng trên Internet và di động hiệu quả về chi phí, có tốc độ nhanh bằng cách sử dụng Dịch vụ AWS và Amazon S3 để lưu trữ dữ liệu sản xuất. Với Amazon S3, bạn có thể tải lên bất kỳ khối lượng dữ liệu nào và truy cập dữ liệu ở mọi nơi để triển khai ứng dụng nhanh hơn và tiếp cận nhiều người dùng cuối hơn. Việc lưu trữ dữ liệu trong Amazon S3 cũng có nghĩa là bạn có quyền truy cập các công cụ, dịch vụ mới nhất về machine learning và phân tích dành cho nhà phát triển AWS để đổi mới và tối ưu hóa ứng dụng dành cho đám mây của bạn.
Các công ty điển hình sử dụng Amazon S3
- Netflix
Netflix phân phối hàng tỷ giờ nội dung đến khách hàng trên khắp thế giới từ Amazon S3. Amazon S3 cũng đóng vai trò là kho dữ liệu cho giải pháp phân tích dữ liệu lớn của họ.
- Finra
FINRA sử dụng Amazon S3 để thu nạp và lưu trữ dữ liệu cho hơn 75 tỷ sự kiện thị trường hàng ngày và các hàm AWS Lambda để định dạng và xác thực dữ liệu dựa trên 200 quy tắc.
- Airbnb
Airbnb để dữ liệu sao lưu và tập tin tĩnh trên Amazon S3, trong đó có trên 10 petabyte hình ảnh người dùng. Là giải pháp được sinh ra trên đám mây, họ liên tục sáng tạo ra nhiều cách thức mới để phân tích dữ liệu được lưu trữ trên Amazon S3.
- GE Healthcare
GE sử dụng Amazon S3 để lưu trữ và bảo vệ một petabyte dữ liệu hình ảnh y tế quan trọng cho dịch vụ Đám mây sức khỏe GE, kết nối hàng trăm nghìn máy chụp và các thiết bị y tế khác.
Amazon S3 có thể lưu trữ những loại dữ liệu (data) nào ?
Với bất kì loại dữ liệu nào và format như thế nào đi chăng nữa, Amazon S3 cũng có thể lưu trữ được hết. Số lượng đối tượng (object) mà Amazon S3 có thể lưu trữ gần như là không có giới hạn, bao gồm dữ liệu, key và metadata.
Tuy không phân biệt kiểu dữ liệu, nhưng Amazon S3 sẽ phân loại các dữ liệu như sau :
- Dữ liệu được truy cập thường xuyên, tần suất cao.
- Dữ liệu không được truy cập thường xuyên, tần suất thấp.
Khi dựa vào cách phân loại dữ liệu như trên thì Amazon sẽ cung cấp nhiều loại hình lưu trữ (AWS S3 Storage Classes) phù hợp cho bạn . Tiêu biểu thì có 3 loại hình lưu trữ :
- Standard : dành cho dữ liệu thường xuyên truy cập, mang lại hiệu suất truy cập tốt hơn và độ trễ thấp hơn. Đây là loại hình lưu trữ mặc định của Amazon S3 khi bạn sử dụng.
- Standard_IA : dành cho dữ liệu ít truy cập. Thường dùng cho các hoạt động backup/restore dữ liệu ứng dụng.
- Glacier : Glacier là một dịch vụ lưu trữ chi phí cực thấp, cung cấp lưu trữ lâu bền với các tính năng bảo mật để lưu trữ và sao lưu dữ liệu. Với Glacier, khách hàng có thể lưu trữ chi phí dữ liệu của họ một cách hiệu quả trong nhiều tháng, nhiều năm hoặc thậm chí nhiều thập kỷ.
Nguồn: https://cuongquach.com/





