The iPhone 6 Review
A8: Apple’s First 20nm SoC
As has been customary for every iPhone launch since the company began publicly naming their SoCs, Apple has once again rolled out a new SoC for their latest line of phones. With the launch of the iPhone 6 series Apple is now up to their eight generation SoC, the appropriately named A8.
After a period of rapid change with the A6 and A7 SoCs – which introduced Apple’s first custom CPU design (Swift) and the first ARMv8 AArch64 design (Cyclone) respectively – A8 is a more structured and straightforward evolution of Apple’s SoC designs. Which is not to say that Apple hasn’t been busy tweaking their designs to extract ever-improved performance and power efficiency, as we’ll see, but our examination of A8 has not uncovered the same kind of radical changes that defined A6 and A7.

The heart and soul of A8 is as always the CPU and GPU. We’ll be taking a look at each of these individually in a moment, but from a high level both of these are evolutions of their predecessors found in A7. Apple’s GPU of choice remains Imagination’s PowerVR, having upgraded from the Series6 based G6430 to Imagination’s newer GX6450 design. Meanwhile Apple continues to develop their own CPUs and A8 packs their latest design, which is an enhanced version of the Cyclone core first introduced in A7.
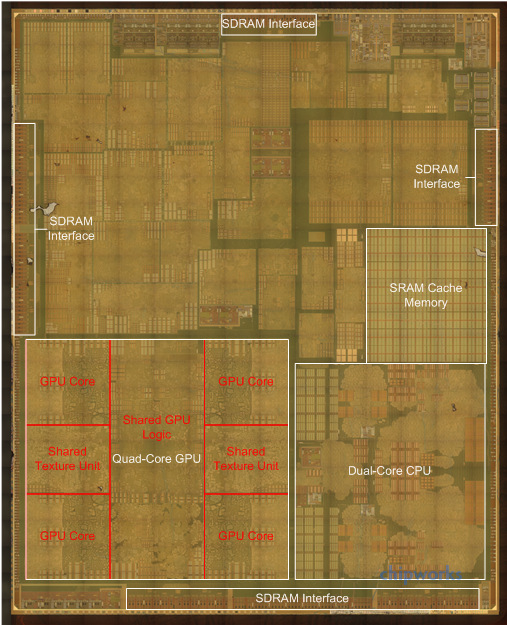
Stepping away from the GPU and CPU for the moment, the biggest change about A8 is that it’s smaller. As discovered by Chipworks, A8 is being fabricated on TSMC’s new 20nm process, making the iPhone 6 among the first smartphones to be shipped with a 20nm SoC.
This move to 20nm is not unexpected, but nonetheless it is considerable for a couple of reasons. The first is that this means Apple has moved production over to TSMC’s 20nm HKMG Planar process, making this the first time an Apple SoC has been manufactured anywhere but a Samsung fab. There are numerous possible reasons for this – and not every reason needs to be technical – but from a process development standpoint it’s important to note that over the last few generations TSMC has been the leader among contract foundries, being the first to get new processes up and running for volume production.
Apple A8 vs A7 SoCs
Apple A8 (2014)
Apple A7 (2013)
Manufacturing Process
TSMC 20nm HKMG
Samsung 28nm HKMG
Die Size
89mm2
102mm2
Transistor Count
~2B
“Over 1B”
CPU
2 x Apple Enhanced Cyclone
ARMv8 64-bit cores
2 x Apple Cyclone
ARMv8 64-bit cores
GPU
IMG PowerVR GX6450
IMG PowerVR G6430
This move is also quite considerable because it means for the first time Apple is manufacturing their SoCs on a bleeding edge manufacturing process. Prior to this Apple has been slow to utilize new manufacturing processes, only finally utilizing a 28nm process in late 2013 for A7 over a year after 28nm first became available. The fact that we are seeing a 20nm SoC from Apple at a time when almost everyone else is still on 28nm indicates just how much the market has shifted over the last few years, and how Apple’s SoC development is now synchronized with the very edge of semiconductor fabrication technology.
Finally, the switch to 20nm is interesting because after the last couple of generations being so-called “half node” jumps – 45nm to 40nm to 32nm to 28nm – the jump from 28nm to 20nm is a full node jump (note that Apple didn’t ever use 40nm, however). This means we are seeing a larger increase in transistor density than in the previous generations, and ideally a larger decrease in power consumption as well.
In practice TSMC’s 20nm process is going to be a mixed bag; it can offer 30% higher speeds, 1.9x the density, or 25% less power consumption than their 28nm process, but not all three at once. In particular power consumption and speeds will be directly opposed, so any use of higher clock speeds will eat into power consumption improvements. This of course gets murkier once we’re comparing TSMC to Samsung, but the principle of clock speed/power tradeoffs remains the same regardless.
Not accounting for minor differences between TSMC and Samsung, in an ideal case Apple is looking at 51% area scaling (the same design on 20nm can be no smaller than 51% of the die area at 28nm). In reality, nothing ever scales perfectly so the density gains will depend on the kind of I/C being laid down (logic, SRAM, etc.). For the complete chip a 60-70% scaling factor is going to be a better approximation, which for Apple means they’ve picked up a lot room to spend on new functionality and reducing their overall die size.
Apple SoC Evolution
CPU Perf
GPU Perf
Die Size
Transistors
Process
A5
~13x
~20x
122m2
<1B
45nm
A6
~26x
~34x
97mm2
<1B
32nm
A7
40x
56x
102mm2
>1B
28nm
A8
50x
84x
89mm2
~2B
20nm
Meanwhile once again this year Apple opened up on die size and transistor counts. A8 weighs in at around 2 billion transistors, as opposed to the “over 1 billion” transistors found on A7. We also have the die size for A8 – 89mm2 – which is some 13% smaller than A7’s 102mm2 die. This makes it clear that Apple has chosen to split their transistor density improvements between adding features/performance and reducing their size, rather than going all-in on either direction.
In the case of using a bleeding edge node this is generally a good call, as Apple and TSMC will need to deal with the fact that chip yields at 20nm will not be as good as they are on the highly mature 28nm process. With lower chip yields, a smaller die will offset some of those yield losses by reducing the number of manufacturing flaws any given die touches, improving the overall yield.

A8 With POP RAM Removed
Moving on, looking at A8 we can see that Apple’s memory subsystem design has not significantly changed from A7. Once again Apple has placed an SRAM cache on the chip to service both the CPU and the GPU. Based on an examination of the die and of latency numbers, this L3 SRAM cache remains unchanged from A7 at 4MB. Meanwhile we also find a series of SDRAM interfaces which drive the A8’s package-on-package (POP) based main memory. Based on teardowns from iFixit, Apple is using 1GB of LPDDR3-1600, the same speed grade of LPDDR3 and capacity that they used for the iPhone 5s. iFixit has found both Hynix and Elpida memory in their phones, so Apple is once again using multiple sources for their RAM.
When we start poking at memory bandwidth we find that memory bandwidths are consistently higher than on A7, but only ever so slightly. This points to Apple having worked out further optimizations to make better use of the memory bandwidth they have available, since as we’ve previously determined they’re still using LPDDR3-1600 speeds.
Geekbench 3 Memory Bandwidth Comparison (1 thread)
Stream Copy
Stream Scale
Stream Add
Stream Triad
Apple A8 1.4GHz
9.08 GB/s
5.37 GB/s
5.76 GB/s
5.78 GB/s
Apple A7 1.3GHz
8.34 GB/s
5.21 GB/s
5.67 GB/s
5.69 GB/s
A8 Advantage
9%
3%
2%
2%
The Stream Copy score ends up being the biggest gain at 9%. Otherwise the rest of the benchmarks only show 2-3% memory bandwidth increases.
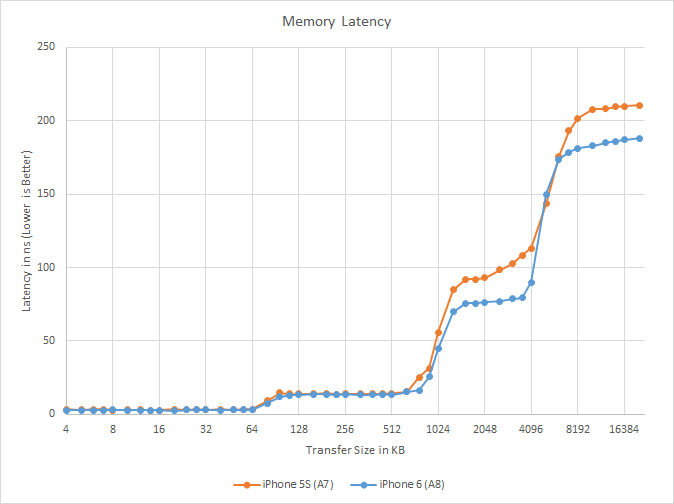
More interesting is memory latency, which shows some unexpected improvements once we get out of the L1 and L2 caches. At both the 1MB – 4MB region of the SRAM and 6MB+ region of main memory, memory latency is consistently lower on A8 versus A7. In both cases we’re looking at latencies about 20ns faster than A7. This identical 20ns gain tells us that that Apple is still doing main memory lookups after the L3 lookup fails, and this in turn means the 20ns gain we’re seeing is due to L3 cache optimizations. We have a couple of ideas for how Apple could have improved L3 latency by nearly 20% like this, but at this time with Apple staying quiet on their architecture like usual, it’s not apparent which of these ideas are the correct ones.
Turning our eyes back to A8 one final time, we find that while a lot of die space is occupied by the CPU, GPU, and SRAM (as we’d expect), there is also quite a bit of space occupied by other blocks Apple has integrated into their design. Without already knowing what you’re looking for these blocks are difficult to identify, but even without being able to do this we have a reasonable idea of what blocks Apple has integrated. Among these we’ll find audio controllers, USB controllers, video encoders/decoders, flash memory controllers, the camera ISP, and of course all kinds of interconnect.
All of these blocks are fixed function hardware (or at best, limited flexibility DSPs), which are equally important to not only the A8’s functionality but power efficiency. By assigning tasks to dedicated hardware Apple does spend some die space on that hardware, but in return these blocks are more efficient than doing those tasks entirely in software. Hence Apple (and SoC designers in general) have a strong incentive to offload as much work as possible to keep power consumption in check. This move towards more fixed function hardware is part of a general “wheel of reincarnation” cycle that has been a constant in processor design over the years, which sees a continuous shift between fixed function and programmable hardware. SoCs, for the most part, are still going towards fixed function hardware, and this should continue for a while yet.

In any case, while we can’t identify individual blocks on A8 we do know that Apple has added a few features to A8 that are present in some form or another among these blocks. New to A8 is some mix of H.265 (HEVC) hardware, which would be necessary to enable the FaceTime over H.265 functionality that is being introduced on the iPhone 6. Apple’s “desktop class scaler” that is used for handling non-native resolution applications and for down-sampling the internal rendering resolution of the iPhone 6 Plus would also be present here.





