Chương 9: Các phương pháp Monte-Carlo (Phần 1)
Trở về Mục lục cuốn sách
Nội Dung Chính
Giới thiệu
Các phương pháp số dùng đến số ngẫu nhiên được gọi là phương pháp Monte-Carlo—đặt tên theo sòng bạc nổi tiếng. Ứng dụng dễ thấy của các phương pháp này là ở trong lĩnh vực vật lý ngẫu nhiên: chẳng hạn nhiệt động học thống kê. Tuy vậy, còn có những ứng dụng khác, khó thấy hơn, chẳng hạn, để ước tính tích phân nhiều chiều.
Số ngẫu nhiên
Không có thuật toán nào đủ khả năng tạo ra dãy số ngẫu nhiên thực sự. Tuy vậy, có những thuật toán phát sinh ra những dãy lặp lại gồm, chẳng hạn, M số nguyên gần như phân bố ngẫu nhiên trong khoảng từ 0 đến M − 1. Ở đây, M là số nguyên (hi vọng là) lớn. Kiểu dãy số này được gọi là giả ngẫu nhiên.
Thuật toán thường gặp nhất để phát sinh các dãy số nguyên giả ngẫu nhiên được gọi là phương pháp đồng dư tuyến tính. Công thức liên hệ giữa các số nguyên thứ n và thứ (n + 1) trong dãy này là:
In + 1 = (A In + C) mod M, [e71]
trong đó A, C, và M là các hằng số nguyên dương. Số thứ nhất trong dãy, còn được gọi là “nhân”, là do người dùng chọn.
Xét một trường hợp ví dụ trong đó A = 7, C = 0, và M = 10. Một dãy số điển hình được phát sinh từ công thức ([e71]) là
I = {3, 1, 7, 9, 3, 1, ⋯}.
Rõ ràng, sự lựa chọn các giá trị A, C, và M như trên là không thật tốt, vì dãy số tự lặp lại chỉ sau bốn vòng lặp. Tuy nhiên, nếu A, C, và M được chọn thích hợp thì dãy có độ dài tối đa (tức là độ dài bằng M), và gần như phân bố ngẫu nhiên trong khoảng từ 0 đến M − 1.
Hàm sau đây được lập để thực hiện phương pháp đồng dư tuyến tính.
// random.cpp
// Linear congruential pseudo-random number generator.
// Generates pseudo-random sequence of integers in
// range 0 .. RANDMAX.
#define RANDMAX 6074 // RANDMAX = M - 1
int random (int seed = 0)
{
static int next = 1;
static int A = 106;
static int C = 1283;
static int M = 6075;
if (seed) next = seed;
next = next * A + C;
return next % M;
}Từ khóa static phía trước lời khai báo biến địa phương cho thấy rằng chương trình phải bảo trì giá trị của biến đó giữa các lần gọi hàm. Nói cách khác, nếu biến tĩnh next có giá trị 999 khi thoát khỏi hàm random thì ở lần gọi hàm này sau đó, next sẽ có giá trị bằng đúng như vậy. Lưu ý rằng giá trị của các biến địa phương không-tĩnh thì không được bảo tồn giữa các lần gọi hàm. Chỉ định = 0 ở dòng đầu của hàm random là giá trị mặc định cho đối số seed. Thực ra, random có thể được gọi theo một trong hai cách. Thứ nhất, random có thể được gọi mà không kèm theo đối số nào: tức là random (): trong trường hợp này, seed được đặt giá trị mặc định bằng 0. Thứ hai, random có thể được gọi với một đối số nguyên, tức là random (n): trong trường hợp này, giá trị của seed được đặt bằng n. Cách gọi random thứ nhất đơn giản là sẽ trả lại số nguyên tiếp theo trong dãy giả ngẫu nhiên. Cách gọi thứ hai đặt nhân cho dãy là giá trị n (tức là I1 được đặt bằng n), rồi trả lại số nguyên tiếp theo trong dãy, tức là I2. Lưu ý rằng nguyên mẫu của hàm random có dạng int random (int = 0): dấu = 0 chỉ định rằng đối số có thể có mặt hoặc không.
Hàm trên trả về một số nguyên giả ngẫu nhiên trong khoảng từ 0 đến RANDMAX (trong đó RANDMAX nhận giá trị M − 1). Để thu được một biến ngẫu nhiên x, phân bố đều trong khoảng từ 0 đến 1, ta cần viết:
x = double (random ()) / double (RANDMAX);Bây giờ nếu x thực sự ngẫu nhiên thì không được có tương quan giữa các giá trị liên tiếp của x. Như vậy, một cách hay để thử nghiệm phương pháp tạo số ngẫu nhiên là vẽ xj theo xj + 1 (trong đó xj tương ứng với số thứ j trong chuỗi giả ngẫu nhiên) với nhiều giá trị khác nhau của j. Để một phương pháp phát sinh số ngẫu nhiên là tốt, đồ thị chấm điểm của nó cần điền kín đặc hình vuông đơn vị. Hơn nữa, cần phải đảm bảo không tồn tại một mẫu họa tiết nào nhận thấy được trong sự phân bố điểm.

Đồ thị chấm điểm của xj theo xj + 1 với j = 1, 10000. Ở đây, xj là các giá trị ngẫu nhiên, phân bố đều trong khoảng từ 0 đến 1, được phát sinh bởi một phương pháp phát sinh số giả ngẫu nhiên đồng dư tuyến tính, được đặc trưng bằng A = 106, C = 1283, và M = 6075.[rand3]
Hình [rand3] cho thấy một đồ thị tương quan cho 10000 cặp xj–xj + 1 đầu tiên phát sinh bằng một phương pháp phát sinh số giả ngẫu nhiên đồng dư tuyến tính, được đặc trưng bởi A = 106, C = 1283, và M = 6075. Có thể thấy rằng đây là một sự lựa chọn dở các giá trị cho A, C, và M, vì dãy số giả ngẫu nhiên tự lặp lại sau vài vòng lặp, dẫn đến các giá trị xj không lấp kín khoảng từ 0 đến 1.

Đồ thị chấm điểm của xj theo xj + 1 với j = 1, 10000. Ở đây, xj là các giá trị ngẫu nhiên, phân bố đều trong khoảng từ 0 đến 1, được phát sinh bởi một phương pháp phát sinh số giả ngẫu nhiên đồng dư tuyến tính, được đặc trưng bằng A = 107, C = 1283, và M = 6075.[rand4]
Hình [rand4] cho thấy một đồ thị tương quan cho 10000 cặp xj–xj + 1 đầu tiên phát sinh bằng một phương pháp phát sinh số giả ngẫu nhiên đồng dư tuyến tính, được đặc trưng bởi A = 107, C = 1283, và M = 6075. Có thể thấy rằng đây là một sự lựa chọn dở các giá trị cho A, C, và M, vì dãy số giả ngẫu nhiên có chiều dài tối đa, cho các giá trị xj phân bố khá đồng đều trong khoảng từ 0 đến 1. Tuy nhiên, nếu nhìn kĩ vào Hình [rand4], ta có thể thấy một xu hướng mờ nhạt cho thấy các điểm chấm xếp theo các hàng ngang và dọc. Điều này cho thấy rằng xj không hoàn toàn phân bố một cách ngẫu nhiên: nghĩa là còn tương quan nào đó giữa các giá trị xj kế tiếp. Vấn đề nằm ở chỗ M quá thấp: nghĩa là sự lựa chọn không đủ rộng rãi cho các giá trị xj khác nhau trong khoảng từ 0 đến 1.

Đồ thị chấm điểm của xj theo xj + 1 với j = 1, 10000. Ở đây, xj là các giá trị ngẫu nhiên, phân bố đều trong khoảng từ 0 đến 1, được phát sinh bởi một phương pháp phát sinh số giả ngẫu nhiên đồng dư tuyến tính, được đặc trưng bằng A = 1103515245, C = 12345, và M = 32768.[rand1]
Hình [rand1] cho thấy một đồ thị tương quan cho 10000 cặp xj–xj + 1 đầu tiên phát sinh bằng một phương pháp phát sinh số giả ngẫu nhiên đồng dư tuyến tính, được đặc trưng bởi A = 1103515245, C = 12345, và M = 32768. Sự tụ tập của các điểm trong hình cho thấy rằng một lần nữa xj không thật sự phân bố một cách ngẫu nhiên. Lần này vấn đề là ở chỗ tràn số nguyên: nghĩa là cá giá trị của A và M đủ lớn khiến cho A In > 1032 − 1 với nhiều số nguyên trong dãy giả ngẫu nhiên. Như vậy, thuật toán ([e71]) đã không được thực thi một cách chính xác.
Sự tràn số nguyên có thể được khắc phục bằng cách dùng thuật toán Schrange. Nếu y = (A z) modM thì
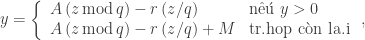
trong đó q = M / A và r = M%A. Phương pháp có tên Park và Miller để phát sinh ra một chuỗi giả ngẫu nhiên tương ứng với phương pháp đồng dư tuyến tính được đặc trưng bởi các giá trị A = 16807, C = 0, và M = 2147483647. Hàm dưới đây thực hiện phương pháp này, dùng thuật toán Schrange để tránh tràn số nguyên.
// random.cpp
// Park and Miller's psuedo-random number generator.
#define RANDMAX 2147483646 // RANDMAX = M - 1
int random (int seed = 0)
{
static int next = 1;
static int A = 16807;
static int M = 2147483647; // 2^31 - 1
static int q = 127773; // M / A
static int r = 2836; // M % A
if (seed) next = seed;
next = A * (next % q) - r * (next / q);
if (next < 0) next += M;
return next;
}
Đồ thị chấm điểm của xj theo xj + 1 với j = 1, 10000. Ở đây, xj là các giá trị ngẫu nhiên, phân bố đều trong khoảng từ 0 đến 1, phát sinh bằng phương pháp giả ngẫu nhiên Park & Miller.[rand2]
Hình [rand2] cho thấy một đồ thị tương quan cho 10000 cặp xj–xj + 1 đầu tiên phát sinh bằng phương pháp Park & Miller. Bây giờ ta thấy được không còn bất kì mẫu họa tiết tiết nào xuất hiện trong các điểm chấm. Điều này cho thấy rằng xj được phân bố ngẫu nhiên trong khoảng từ 0 đến 1. Từ giờ trở đi, ta sẽ dùng phương pháp Park & Miller để phát sinh tất cả số giả ngẫu nhiên cần thiết khi nghiên cứu các phương pháp Monte-Carlo.
Hàm phân phối
Đặt P(x) dx là xác suất tìm thấy biến ngẫu nhiên x trong khoảng từ x đến x + dx. Ở đây, P(x) được gọi là mật độ xác suất. Lưu ý rằng P = 0 tương ứng với không có khả năng, còn P = 1 tương ứng với chắc chắn. Vì chắc chắn là có giá trị của x nằm trong khoảng từ − ∞ đến + ∞ nên các mật độ xác suất đều chịu ràng buộc chuẩn hóa sau đây
∫−∞+∞P(x) dx = 1.
Giả sử rằng ta muốn lập một biến ngẫu nhiên x phân bố đều trong khoảng từ x1 đến x2. Nói cách khác, mật độ xác suất của x là
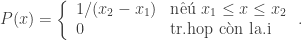
Một biến như vậy được lập như sau
x = x1 + (x2 - x1) * double (random ()) / double (RANDMAX);Có hai cách cơ bản để ta lập biến ngẫu nhiên phân bố không đều: phương pháp biến đổi và phương pháp bác bỏ. Ta sẽ lần lượt nghiên cứu từng phương pháp này.
Trước hết, ta hãy xét phương pháp chuyển đổi. Đặt y = f(x), trong đó f là một hàm đã biết, còn x là một biến ngẫu nhiên. Giả sử rằng mật độ xác suất của x là Px(x). Khi đó mật độ xác suất Py(y) của y là gì? Quy tắc cơ bản ở đây là bảo toàn xác suất:
∣Px(x) dx∣ = ∣Py(y) dy∣.
Nói cách khác, xác suất tìm được x trong khoảng từ x đến x + dx cũng bằng xác suất tìm được y trong khoảng từ y đến y + dy. Từ đó rút ra
Py(y) = Px(x) / ∣fʹ(x)∣,
trong đó fʹ = df / dx.
Chẳng hạn, ta hãy xét phân bố Poisson:
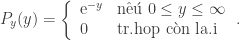
Đặt y = f(x) = − lnx, khi đó ∣fʹ∣ = 1 / x. Giả sử rằng

Từ đó dẫn đến
Py(y) = 1 / ∣fʹ∣ = x = e − y,
với x = 0 ứng với y = ∞, và x = 1 ứng với y = 0. Ta kết luận rằng nếu
x = double (random ()) / double (RANDMAX);
y = - log (x);thì y có phân bố tuân theo dạng phân bố Poisson.
Phương pháp chuyển đổi yêu cầu một hàm phân bố xác suất khả vi. Điều này không phải lúc nào cũng có được. Trong những trường hợp như vậy, ta có thể dùng phương pháp bác bỏ.
Giả sử rằng ta muốn một biến ngẫu nhiên y phân bố với mật độ Py(y) trong khoảng ymin đến ymax. Đặt Py max là giá trị lớn nhất của P(y) trong khoảng này (xem Hình [rej]). Phương pháp bác bỏ là như sau. Biến y được lấy mẫu một cách ngẫu nhiên trong khoảng từ ymin đến ymax. Với mỗi giá trị của y, đầu tiên ta lượng giá Py(y). Sau đó ta phát sinh một số ngẫu nhiên x phân bố đều trong khoảng từ 0 đến Py max. Cuối cùng, nếu Py(y) < x thì ta bác bỏ giá trị y; còn nếu ngược lại thì ta giữ nó. Ở trường hợp sau này, y sẽ được phân bố theo Py(y).

Phương pháp bác bỏ.[rej]
Lấy ví dụ, ta hãy xét phân bố Gauss:
![\displaystyle{ P_y(y) =\frac{\textrm{exp}[(y-\bar{y})^2/2\,\sigma^2]}{\sqrt{2\pi}\,\sigma},}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B++P_y%28y%29+%3D%5Cfrac%7B%5Ctextrm%7Bexp%7D%5B%28y-%5Cbar%7By%7D%29%5E2%2F2%5C%2C%5Csigma%5E2%5D%7D%7B%5Csqrt%7B2%5Cpi%7D%5C%2C%5Csigma%7D%2C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
trong đó ȳ là giá trị trung bình của y, và σ là độ lệch chuẩn. Đặt
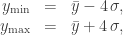
vì có một khả năng nhỏ đến mức bỏ qua được, là y sẽ nằm lệch khỏi giá trị trung bình xa hơn 4 lần độ lệch chuẩn. Từ đó dẫn đến
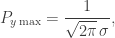
với cực đại xảy ra ở y = ȳ . Hàm được lập trình dưới đây sử dụng phương pháp bác bỏ để trả về một biến ngẫu nhiên tuân theo dạng phân bố Gauss với trị trung bình mean và độ lệch chuẩn sigma:
// gaussian.cpp
// Function to return random variable distributed
// according to Gaussian distribution with mean mean
// and standard deviation sigma.
#define RANDMAX 2147483646
int random (int = 0);
double gaussian (double mean, double sigma)
{
double ymin = mean - 4. * sigma;
double ymax = mean + 4. * sigma;
double Pymax = 1. / sqrt (2. * M_PI) / sigma;
// Calculate random value uniformly distributed
// in range ymin to ymax
double y = ymin + (ymax - ymin) * double (random ()) / double (RANDMAX);
// Calculate Py
double Py = exp (- (y - mean) * (y - mean) / 2. / sigma / sigma) /
sqrt (2. * M_PI) / sigma;
// Calculate random value uniformly distributed in range 0 to Pymax
double x = Pymax * double (random ()) / double (RANDMAX);
// If x > Py reject value and recalculate
if (x > Py) return gaussian (mean, sigma);
else return y;
}Hình [rej1] minh họa sự thể hiện của hàm kia trong quá trình chạy. Có thể thấy rằng hàm đã thành công trong việc trả lại một giá trị ngẫu nhiên tuân theo phân bố Gauss.

Một triệu giá trị trả lại từ hàm gaussian với mean = 5. và sigma = 1,25. Các giá trị được chia vào 100 ngăn, mỗi ngăn có bề rộng bằng 0,1. Hình vẽ cho thấy số điểm trong mỗi ngăn sau khi chia cho một hệ số chuẩn hóa thích hợp. Một đường cong Gauss cũng được vẽ cùng để tiện so sánh.[rej1]
Tích phân Monte-Carlo
Xét tích phân một chiều: ∫xlxh f(x) dx. Ta có thể ước tính số trị tích phân này bằng cách chi khoảng từ xl đến xh thành N đoạn đều nhau với bề rộng
h = (xh − xl) / N.
Đặt xi là trung điểm của đoạn thứ i, và đặt fi = f(xi). Từ đó giá trị xấp xỉ của tích phân có dạng
∫ xlxh f(x) dx ≃ ∑ i=1N fi h
Phương pháp tích phân này—vốn được biết với tên phương pháp trung điểm—không thật chính xác, nhưng rất dễ khái quát hóa cho tích phân nhiều chiều.
Sai số gắn với phương pháp trung điểm là gì? À, sai số tổng hợp thì bằng tích của từng sai số trên từng đoạn, O(h2), với số đoạn chia, O(h−1). Sai số mỗi đoạn chia hình thành từ sự biến đổi tuyến tính của f(x) trong mỗi đoạn chia. Như vậy, sai số tổng thể là O(h2) × O(h−1) = O(h). Vì, h ∝ N−1, ta có thể viết
∫ xlxh f(x) dx ≃ ∑ i=1Nfi h + O(N−1).
Bây giờ ta hãy xét tích phân hai chiều. Chẳng hạn, diện tích giới hạn bởi một đường cong [hình cong]. Ta có thể tính tích phân như vậy bằng cách chia không gian thành các ô vuông cùng kích thước h, rồi đếm số ô vuông có tâm điểm nằm trong phạm vi đường cong, chẳng hạn được N ô vuông. Khi đó, xấp xỉ cho tích phân có dạng
A ≃ N h2.
Đây là khái quát hóa cho phương pháp trung điểm trong trường hợp hai chiều.
Sai số gắn với phương pháp trung điểm trong trường hợp hai chiều bằng bao nhiêu? À sai số này phát sinh từ các ô vuông bị cắt bởi qua bởi đường cong. Những ô vuông hoặc là đóng góp hoàn toàn, hoặc là không đóng góp gì vào giá trị tích phân, tùy theo tâm của chúng nằm trong hay nằm ngoài hình đường cong. Trên thực tế, chỉ những phần của ô vuông bị cắt qua mà nằm trong hình cong thì mới đóng góp vào giá trị tích phân. Do vậy, sai số bằng tích giữa diện tích của một ô cho trước, O(h2), với số ô giao cắt bởi đường cong, O(h−1). Vì vậy, sai số tổng hợp là O(h2) × O(h−1) = O(h) = O(N−1/2). Từ đó, ta có thể viết
A = N h2 + O(N−1/2).
Bây giờ ta hãy xét tích phân ba chiều. Chẳng hạn, thể tích bao bọc trong một mặt cong. Ta có thể tính tích phân như vậy bằng cách chia không gian thành những khối lập phương giống nhau có kích thước h, rồi đếm số lập phương (chẳng hạn, N) có tâm nằm bên trong của mặt cong đó. Lúc này, xấp xỉ cho tích phân có dạng
V ≃ N h3.
Đây là khái quát hóa cho phương pháp trung điểm trong trường hợp ba chiều. À, sai số này phát sinh từ các khối lập phương bị cắt qua bởi mặt cong. Những khối lập phương này hoặc là đóng góp hoàn toàn, hoặc là không góp gì vào giá trị tích phân, tùy theo điểm tâm của chúng có nằm trong mặt cong hay không. Trên thực tế, chỉ những phần khối lập phương bị cắt qua mà nằm trong mặt cong mới đóng góp vào giá trị tích phân. Do vậy, sai số bằng tích giữa thể tích của một khối lập phương cho trước, O(h3), với số các khối bị giao cắt bởi mặt cong, O(h−2). Vì vậy, sai số tổng hợp là O(h3) × O(h−2) = O(h) = O(N−1/3). Từ đó, ta có thể viết
V = N h3 + O(N−1/3).
Sau cùng, ta hãy xem xét việc dùng phương pháp trung điểm để ước lượng thể tích, V, của một siêu khối d-chiều, bao quanh bởi siêu mặt (d − 1)-chiều. Rõ ràng là, từ những ví dụ trên, ta có
V = N hd + O(N−1/d),
trong đó N là số siêu lập phương giống hệt nhau mà siêu khối đã bị chia ra. Lưu ý rằng sai số giảm sút theo N ngày càng chậm hơn khi số chiều, d, tăng lên. Lời giải thích cho hiện tượng này khá đơn giản. Giả sử rằng N = 106. Với N = 106 ta có thể chia một đoạn thẳng có chiều dài đơn vị thành các đoạn con có độ đo tuyến tính [chính là chiều dài] bằng 10−6, nhưng chỉ có thể chia một diện tích đơn vị thành những phần nhỏ có độ đo tuyến tính bằng 10−3, và thể tích đơn vị thành các phần nhỏ có độ đo tuyến tính bằng 10−2. Như vậy, với số các đoạn chia là cố định thì khoảng cách lưới chia (và do đó, sai số tích phân) tăng một cách đáng kể khi số chiều tăng lên.
Bây giờ ta hãy xét đến cái gọi là phương pháp Monte-Carlo để tính tích phân nhiều chiều [nhiều lớp]. Chẳng hạn, xét việc tính diện tích A, bao quanh bởi đường cong C. Giả sử rằng đường cong nằm trọn trong một miền đơn giản nào đó, có diện tích Aʹ, như minh họa trên Hình [fmc]. Ta hãy phát sinh Nʹ điểm phân bố ngẫu nhiên trong khắp diện tích Aʹ. Giả sử rằng N điểm trong số đó nằm phía trong đường cong C. Khi đó ước tính diện tích bao bởi đường cong đơn giản là
A = (N / Nʹ) Aʹ. [emc]

Phương pháp tích phân Monte-Carlo.[fmc]
Sai số gắn với phương pháp tích phân Monte-Carlo bằng bao nhiêu? À, mỗi điểm có một xác suất p = A / Aʹ là nằm phía trong đường cong. Vì vậy, việc xác định xem một điểm cho trước có nằm phía trong đường cong hay không cũng giống với đo một biến ngẫu nhiên có hai giá trị có thể: 1 (tương ứng với điểm nằm phía trong đường cong) với xác suất p, và 0 (tương ứng với điểm nằm phía ngoài đường cong) với xác suất 1 − p. Nếu ta thực hiện Nʹ lần đo với x (nghĩa là, nếu ta rải Nʹ điểm trên khắp Aʹ) thì số điểm nằm phía trong đường cong là
N = ∑ i = 1Nʹxi,
trong đó xi biểu diễn lần đo thứ i của x. Bây giờ, giá trị trung bình của N là
N̄ = ∑ i=1Nʹx̄ = Nʹ x̄,
trong đó
x̄ = 1 × p + 0 × (1 − p) = p.
Vì vậy,
N̄ = Nʹ p = Nʹ A / Aʹ;
kết quả này thống nhất với PT ([emc]). Ta kết luận rằng, xét trung bình, một phép đo của N sẽ dẫn đến kết quả đúng. Nhưng, độ phân tán trong phép đo như vậy bằng bao nhiêu? À, nếu σ biểu thị cho độ lệch chuẩn của N thì ta có
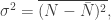
vốn cũng có thể viết là
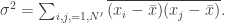
Tuy nhiên, 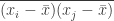


Bây giờ,

và
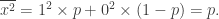
Do đó,
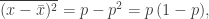
cho ta
σ = √[Nʹ p (1 − p)].
Sau cùng, vì các giá trị mà N dễ nhận được rơi vào trong khoảng N = N̄ ± σ nên ta có thể viết

Từ PT ([emc]), sẽ dẫn đến
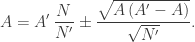
Nói cách khác, sai số có độ lớn cỡ (Nʹ) − 1 / 2.
Phương pháp Monte-Carlo có thể được khái quát quá ngay cho d-chiều. Chẳng hạn, xét một siêu khối trong d-chiều có thể tích V được giới hạn bởi siêu mặt A, (d − 1)-chiều. Giả sử rằng A nằm trọn vẹn trong một siêu thể tích Vʹ đơn giản nào đó. Ta có thể phát sinh ngẫu nhiên Nʹ điểm phân bố khắp Vʹ. Gọi N là số những điểm nằm trong A. Từ đó dẫn đến công thức ước tính V đơn giản là
V = (N / Nʹ) Vʹ.
Bây giờ, trong khi suy diễn PT ([e999]), không có gì phụ thuộc vào dữ kiện hai chiều của tích phân đang xét. Vì vậy, ta có thể khái quát hóa phương trình này để nhận được
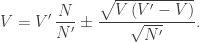
Ta kết luận rằng sai số gắn với tích phân Monte-Carlo luôn luôn có độ lớn cỡ (Nʹ)−1/2, bất kể số chiều của tích phân là bao nhiêu.
Bây giờ đến lúc chúng ta so sánh và làm rõ sự khác biệt giữa các phương pháp trung điểm và Monte-Carlo để tính tích phân nhiều chiều. Trong phương pháp trung điểm, ta lấp đầy không gian với một lưới chia cách đều gồm, chẳng hạn N điểm (nghĩa là các trung điểm của từng đoạn chia); sai số tổng hợp sẽ có độ lớn cỡ N−1/d, trong đó d là số chiều của tích phân. Trong phương pháp Monte-Carlo, ta lấp đầy không gian với, chẳng hạn N điểm chấm phân bố ngẫu nhiên, và sai số tổng hợp sẽ có độ lớn cỡ N−1/2, không phụ thuộc vào số chiều của tích phân. Đối với tích phân một chiều (d = 1), phương pháp trung điểm hiệu quả hơn phương pháp Monte-Carlo, vì với phương pháp đầu, sai số có độ lớn cỡ N−1, còn ở phương pháp sau sai số có độ lớn cỡ N−1/2. Với tích phân hai chiều (d = 2), hai phương pháp trung điểm và Monte-Carlo hiệu quả như nhau, vì trong cả hai trường hợp sai số có độ lớn cỡ N−1/2. Sau cùng, với tích phân ba chiều (d = 3), phương pháp trung điểm kém hiệu quả so với phương pháp Monte-Carlo, vì sai số có độ lớn cỡ N−1/3, so với N−1/2 của phương pháp sau. Ta kết luận được rằng trong trường hợp số chiều đủ lớn thì tính tích phân theo phương pháp Monte-Carlo sẽ luôn hiệu quả hơn một phương pháp tổng hợp (như phương pháp trung điểm) dựa trên một lưới cách đều.

Ví dụ tính toán: thể tích của một khối cầu 2 chiều có đường kính đơn vị nội tiếp trong khối lập phương 2 chiều.[exam]
Cho tới giờ, ta mới chỉ xét đến cách dùng phương pháp Monte-Carlo để tính một lớp khá đặc biệt gồm các tính phân trong đó hàm tích phân chỉ có thể nhận giá trị 0 hoặc 1. Tuy nhiên, phương pháp Monte-Carlo có thể dễ dàng được điều chỉnh để ước tính được những tích phân tổng quát hơn. Giả sử rằng ta cần tính ∫ f dV, trong đó f là một hàm tổng quát và miền cũng tích phân nằm trong số chiều bất kì. Ta tiến hành bằng việc rải một cách ngẫu nhiên N trên khắp miền lấy tính phân rồi tính f tại mỗi điểm. Đặt xi là điểm thứ i. Xấp xỉ Monte-Carlo cho tích phân chỉ đơn giản là
∫ f dV = (1/N) ∑ i=1Nf(xi) + O(1 / √N).

Sai số tích phân, ε, theo số điểm chia lưới, N, đối với ba tích phân tính theo phương pháp trung điểm. Các tích phân là diện tích của một hình tròn bán kính bằng đơn vị (biểu thị bởi đường nét liền), thể tích của một khối cầu bán kính đơn vị (nét chấm chấm), và siêu thể tích của một khối cầu trong không gian 4 chiều có bán kính đơn vị (nét gạch đứt).[midpoint]
Chúng ta kết thúc mục này bằng một bài toán ví dụ. Ta hãy tính thể tích của một khối cầu d-chiều có bán kính bằng 1 đơn vị, trong đó d chạy từ 2 đến 4, bằng cả hai cách trung điểm và Monte-Carlo methods. Với cả hai cách, miền lấy tích phân là khối lập phương ngoại tiếp khối cầu, xem Hình [exam].

Sai số tích phân, ε, theo số điểm, N, đối với ba tích phân tính theo phương pháp Monte-Carlo. Các tích phân là diện tích của một hình tròn bán kính bằng đơn vị (biểu thị bởi đường nét liền), thể tích của một khối cầu bán kính đơn vị (nét chấm chấm), và siêu thể tích của một khối cầu trong không gian 4 chiều có bán kính đơn vị (nét gạch đứt).[montecarlo]
Hình [midpoint] cho thấy sự phụ thuộc của sai số tích phân ứng với phương pháp trung điểm vào số điểm chia, N. Có thể thấy rằng khi số chiều của tích phân tăng lên thì sai số giảm bớt không nhanh bằng tốc độ tăng của N.
Hình [montecarlo] cho thấy sự phụ thuộc của sai số tích phân ứng với phương pháp Monte-Carlo vào số điểm chia, N. Có thể thấy rằng có rất ít thay đổi ở mức độ giảm sai số khi N tăng, với các số chiều lấy tích phân khác nhau. VÌ vậy, khi số chiều d tăng lên, phương pháp Monte-Carlo cuối cùng sẽ vượt trội phương pháp trung điểm.
Đánh giá:
Share this:
Thích bài này:
Thích
Đang tải…





